I was exploring GKE or Google Kubernetes Engine recently. Google Cloud has pretty good UI interface where you can deploy workloads & services without having to define your own YAML file. You can completely skip kubectl command line if you are starting as a Kubernetes beginner. You can just follow the UI steps. UI is well defined. I deployed one application in GKE cluster from UI. Everything was fine. Three pods got deployed successfully & they were in running state. But I noticed one thing while exploring deployment OVERVIEW tab. K8s Autoscaler was not working. I saw a message saying “Status Unable to read all metrics” in AutoScaler section.
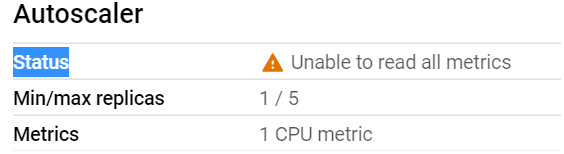
But I could see that CPU metrics of pods were getting tracked by GKE properly.
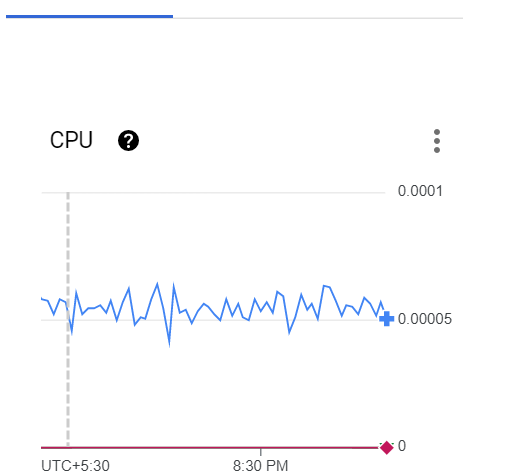
So what can be the problem? How can Kubernetes autoscaler not read the metrics when the K8s cluster is tracking & showing the same metrics properly?
After a bit of investigation, I found a problem with YAML file generated by GKE. In K8s deployment yaml file, the resources field was empty. When Google Cloud UI was taking inputs for new deployment, it should have asked for the details to populate resources field. This field tells autoscaler what resource limit is requested by one pod. Resource can be CPU & memory. It will define maximum CPU or memory utilization of a pod. Beyond that, autoscaler will create new pod to scale out. Part of the YAML file looked like below:
spec:
containers:
- image: test/image1:latest
imagePullPolicy: Always
name: catalogue-1
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: FileAs resource utilization limit was not set in deployment YAML file, autoscaler didn’t know when to scale out or scale down a replica set. If it can’t detect resource limit, it can’t scale out when that limit is breached. It is as simple as that.
To fix this, I just added CPU limit to 500m & updated deployment YAML file. Now the same section looked similar to below:
spec:
containers:
- image: test/image1:latest
imagePullPolicy: Always
name: carts-1
resources:
requests:
cpu: 500m
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: FileOnce the updated workload got redeployed, autoscaler started working. From yellow, it became green.
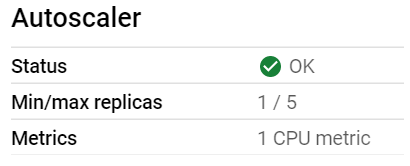
So if you face same kind of problem with your Horizontal Pod Autoscaler (HPA), just check the above steps & make sure you are not doing the same mistake.